Blog / How web scraping is useful in finding Amazon customer reviews
11 April 2022
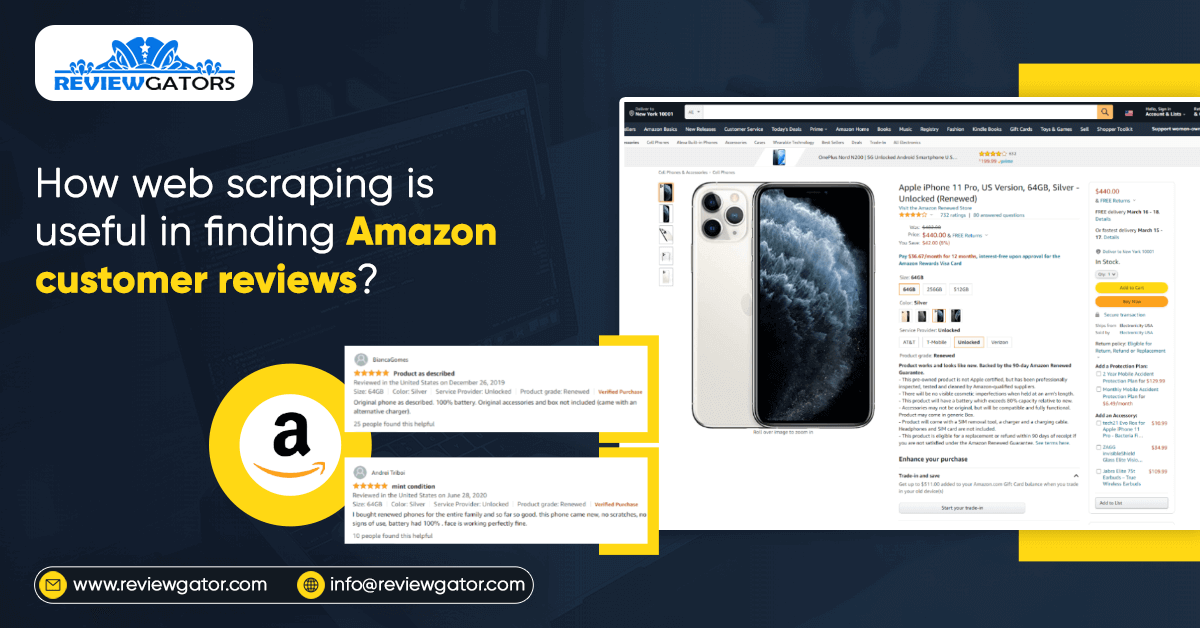
The Internet is used to search for many things. These details are readily available, but it is difficult to store the same for later use.
One option is to manually copy the data and store it on your desktop. This is, however, an extremely time-consuming task. In such circumstances, web scraping plays an important role.
Web scraping is a method of extracting vast amounts of information from websites and saving it to your computer. This information can be analyzed afterward.
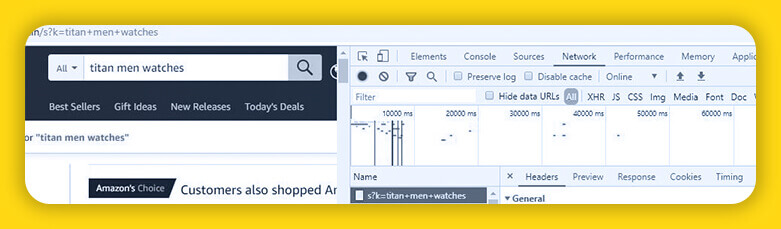
The first step is to determine whether data scraping is permitted on the website or not. This can be verified by including robots.txt at the end of the website's URL.
https://www.amazon.in/robots.txt
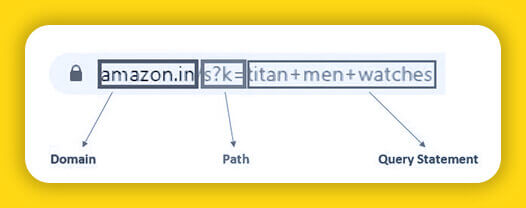
Protocol, domain, path, query-string, and fragment are the five parts of a URL. However, we will concentrate on three components: domain, path, and query string.
STAGES:
Let's start coding right away!!
import requests
from bs4 import BeautifulSoup
We'll start by importing the two libraries mentioned above. The library ‘Import requests’ method is used to retrieve information from a website. In which we request the URL and receive an answer. Along with the web page content, the answer will also provide a status code. The contents of a page are converted into an appropriate format by another library BeautifulSoup.
In most cases, python queries don't require headers or cookies. But in some instances when we request the page content, we obtain a status code of 403 or 503. This implies access is not given to that web page. In these circumstances, we include headers and cookies to the request argument. get() is a function that returns a value.
Go to Amazon and search for a certain product to find your headers and cookies. Then right-click any element and select Inspect (or use the shortcut key Ctrl+Shift+I). Headers and cookies can be found under the Network tab.
Don’t share cookies.
The page content and status code for the needed query are obtained using a function. To continue with the process, a status code of 200 is needed.
def getAmazonSearch(search_query):
url="https://www.amazon.in/s?k="+search_query
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
Every item on Amazon has a number called a unique identification number. The ASIN (Amazon Standard Identification Number) is the name given to this number. We may have direct access to each product by using the ASIN number.
The product names and ASIN numbers can be extracted using the mentioned function.
data_asin=[]
response=getAmazonSearch('titan+men+watches')
soup=BeautifulSoup(response.content)
for i in soup.findAll("div",{'class':"sg-col-4-of-24 sg-col-4-of-12 sg-col-4-of-36 s-result-item sg-col-4-of-28 sg-col-4-of-16 sg-col sg-col-4-of-20 sg-col-4-of-32"}):
data_asin.append(i['data-asin'])
The findall() function is used to locate all the HTML tags of the needed span, attribute, and value as specified in the parameter. These tag settings will be the same for all product names and asins on all product pages. Data ASIN content is just added to create a new list. We can access individual data-asin numbers and their respective sites using this list.
def Searchasin(asin):
url="https://www.amazon.in/dp/"+asin
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
We now proceed in the same manner as we did with ASIN numbers. Using the corresponding HTML tag, we extract all of the 'see all customer reviews' links for each product and add the href component to a new list.
link=[]
for i in range(len(data_asin)):
response=Searchasin(data_asin[i])
soup=BeautifulSoup(response.content)
for i in soup.findAll("a",{'data-hook':"see-all-reviews-link-foot"}):
link.append(i['href'])

We now have all the links for each product. We can scrape all of the product reviews using these links. As a result, we create a function (same as previous functions) that extracts all the product reviews.
def Search reviews(review_link):
url="https://www.amazon.in"+review_link
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
All of the customer reviews are extracted and stored in a list using the above-defined procedure.
reviews=[]
for j in range(len(link)):
for k in range(100):
response=Searchreviews(link[j]+'&pageNumber='+str(k))
soup=BeautifulSoup(response.content)
for i in soup.findAll("span",{'data-hook':"review-body"}):
reviews.append(i.text)
By adding '&page=2 or 3 or 4.' to the search query and repeating the procedures from scraping ASIN numbers, we can retrieve the details of any number of product pages.
Now when we have scraped all the reviews, we need to put them in a file so that we can analyze them further.
rev={'reviews':reviews} #converting the reviews list into a dictionary
review_data=pd.DataFrame.from_dict(rev) #converting this dictionary into a dataframe
review_data.to_csv('Scraping reviews.csv',index=False)
We make a dictionary out of the reviews list. Then, to turn the dictionary into a data frame, Import the pandas package and utilize it. We then convert it to a CSV file and save it on a computer using the to_ CSV() function.
Looking for Amazon Customer Reviews Scraping services? Contact us now!
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2026 ReviewGators, All rights reserved.
Disclaimer : Reviewgators.com only extracts or scrape the information or the data that is publicly available as well as does not scrape personal or identity-related information.
