
The demand for data extraction from websites is growing. We usually need to record data from websites when working on data-related tasks like pricing monitoring, business analytics, or news aggregation. Copying and pasting information line by line, on the other hand, has become redundant. In this blog, we'll show you how to accomplish web scraping using Python to become an "insider" in scraping data from websites.
Web scraping is a technique for extracting huge amounts of data from websites. But why is it necessary to acquire such large amounts of data from websites? Let's have a look at several web scraping applications to learn more about this:

Web scraping services like ReviewGators scrape data from online shopping sites and apply it to compare product prices.

Web scraping is used by many firms that utilize email as an advertising medium to obtain email IDs and then send mass emails.

To figure out what's popular, web scraping is utilized to extract information from social media platforms like Twitter.

Web scraping is a technique for gathering large amounts of data (statistics, general information, temperature, and so on) from web pages, which is then processed and used in surveys or R&D.

Details about job vacancies and interviews are gathered from several websites and then compiled in one spot for easy access by the user.
Flexibility: Python is a simple to learn the language that is very productive and dynamically imputable. As a result, people could easily update their code and keep up with the speed of online upgrades.
Powerful: Python comes with a huge number of mature libraries. Beautifulsoup4 may, for example, assist us in retrieving URLs and extracting data from web pages. By allowing web crawlers to replicate human browsing behavior, Selenium could help us escape some anti-scraping tactics. Furthermore, re, numpy, and pandas may be able to assist us in cleaning and processing the data.
Let us start with web scraping using Python.
Web scraping is a method for converting unstructured HTML data to structured data in a spreadsheet or database. Some large websites, such as Airbnb or Twitter, would make APIs available to developers so that they could access their data. The API (Application Programming Interface) is a way for two apps to communicate with one another. For most users, using an API to get data from a website is the most efficient way to do so.
The majority of websites, however, lack API services. Even if they give an API, the data you may receive may not be what you need. As a result, building a python script to create a web crawler is an additional powerful and flexible option.
1. In this blog, we will scrape reviews from Yelp. BeautifulSoup in bs4 and request in urllib will be used. These two libraries are frequently used in Python web crawler development. The first step is to import these two modules into Python such that we can make use of their functionalities.

2. Extracting the HTML from web page
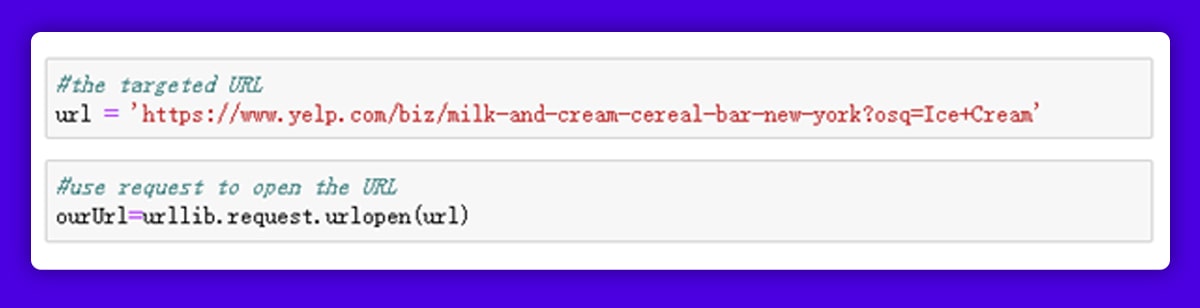
We need to get information from " https://www.yelp.com/biz/milk-and-cream-cereal-bar-new-york?osq=Ice+Cream " Let's start by storing the URL in a variable named URL. Then, using the urlopen() function in request, we could retrieve the content on this URL and save the HTML in "ourUrl."
We will then apply BeautifulSoup to parse the page.

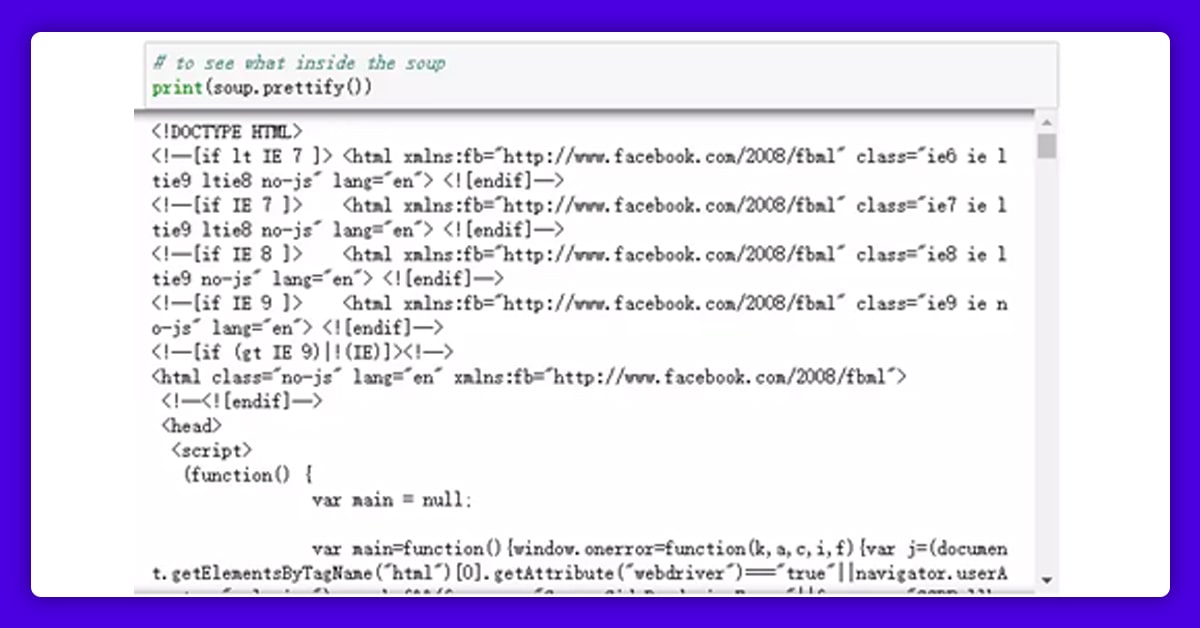
We could use a function called prettify() to clean the raw data and output it to view the hierarchical structure of HTML in the "soup" now that we have the "soup," which is the raw HTML for this website.
The next step is to locate the HTML reviews on this page, extract them, and save them. A unique HTML "ID" would be assigned to each element on the web page. We'd have to INSPECT them on a web page to check their ID.
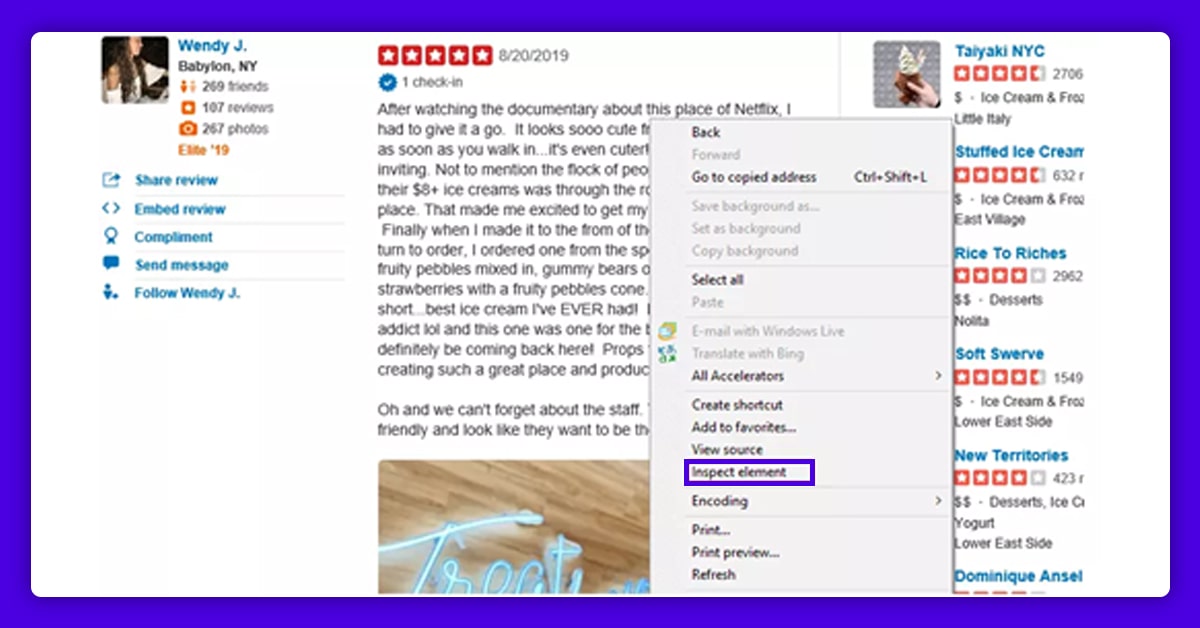
We could examine the HTML of the reviews after clicking "Inspect element" (or "Inspect" depending on the browser).
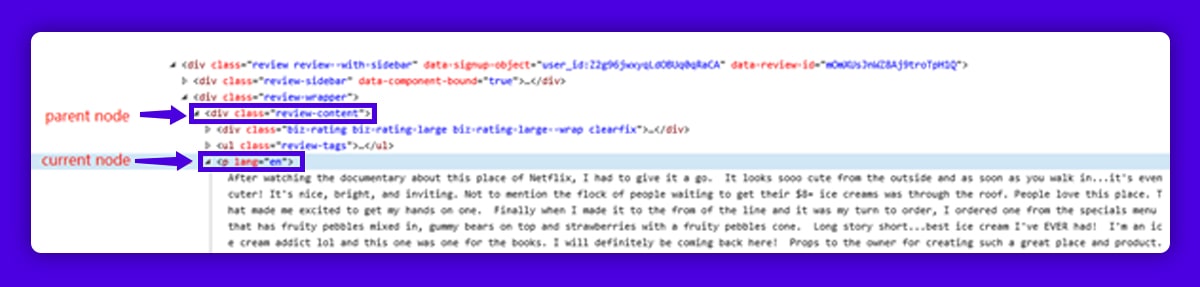
The reviews in this case can be found underneath the tag "p." To discover the parent node of these reviews, we'll first utilize the find all() function. Then, in a loop, find all elements having the tag "p" under the parent node. We'd put all of the "p" elements in an empty list called "review" when we found them all.
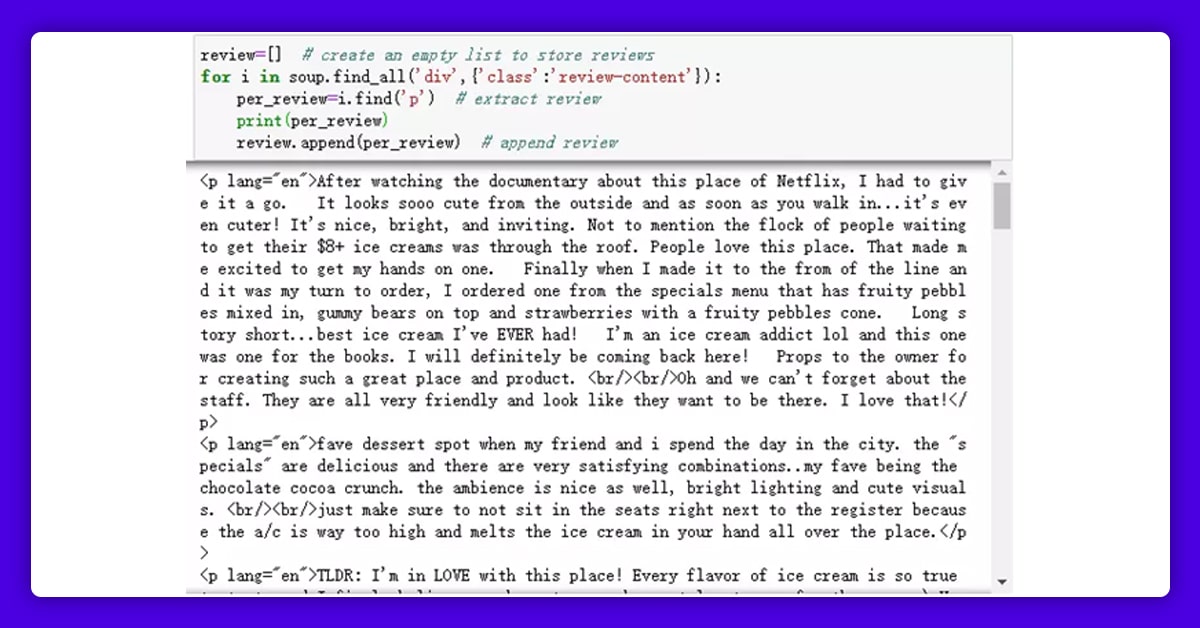
We now have access to all of the reviews on that page. Let's check how many reviews we've gotten thus far.

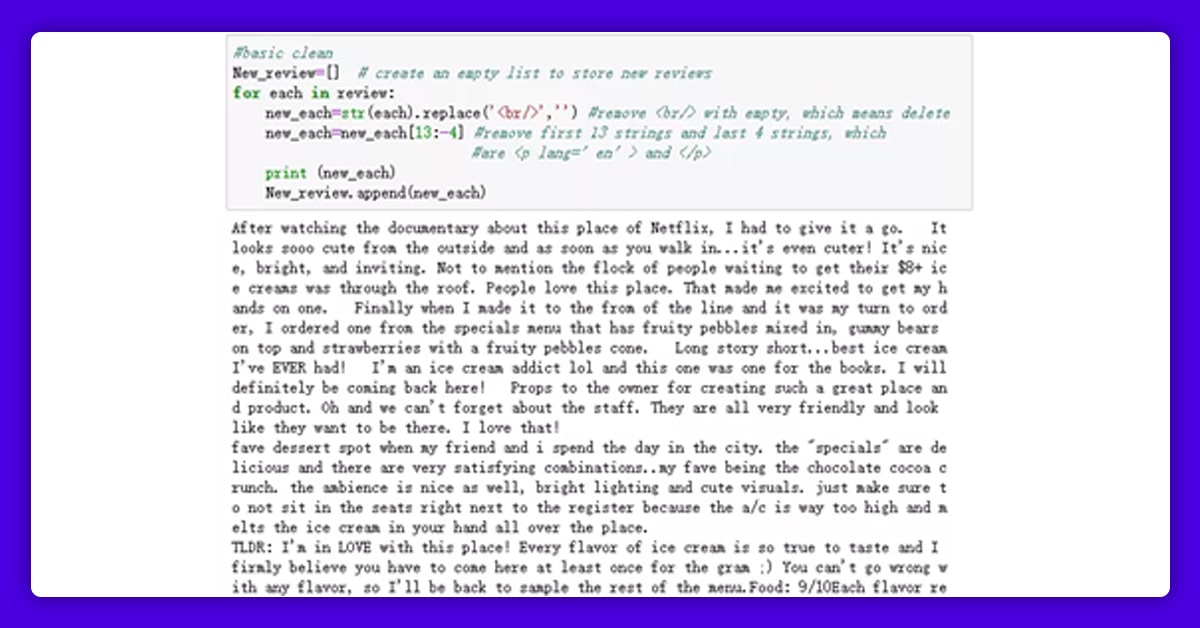
You should notice that some unnecessary text remains, such as "p lang='en'>" at the start of each review, "br/>" in the middle of the reviews, and "/p>" at the end of each review. A single line break is indicated by the character "br/>." We won't require any line breaks in the reviews, thus they'll be removed. Also, "p lang='en'>" and "/p>" are the beginning and end of the HTML, respectively, and must be removed.
If you are in search for simple process of web scraping, you can contact ReviewGators today!!
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2026 ReviewGators, All rights reserved.
Disclaimer : Reviewgators.com only extracts or scrape the information or the data that is publicly available as well as does not scrape personal or identity-related information.
