Blog / A Comprehensive Guide to Scraping TripAdvisor.com in 2023
22 March 2023

TripAdvisor is one of the world's largest travel websites, providing millions of users with valuable insights on hotels, restaurants, and other attractions in thousands of cities worldwide. As a data enthusiast, you might be interested in using TripAdvisor's data for various purposes, such as market research or competitor analysis.
However, manually collecting data from TripAdvisor can take time and effort, which is where web scraping comes in. This blog post will explore the ins and outs of web scraping TripAdvisor.com, including its benefits, legal considerations, and step-by-step instructions to scrape TripAdvisor review data using Python. Whether you're a data scientist, market researcher, or someone who loves exploring the world through data, this post is for you.

Web scraping refers to the process of extracting useful information from websites. Web scraping can be helpful in several scenarios, such as market research, data mining, and analyzing competitors' prices. However, one of the main reasons why many businesses choose to scrape websites is to save time and effort by automating manual processes. Before we get into the details, let's have a quick overview of web scraping in general.
In summary, web scraping is a method of extracting valuable data from websites. There are two main approaches to web scraping: browser automation and software that runs on the server side. While browser automation can be suitable for beginners, users must manually perform some steps on the website they want to scrape. Software that runs on the server side is typically better for advanced users, as it works seamlessly with other tools and applications available. However, programming skills are required; otherwise, this approach will be more complicated than browser automation.
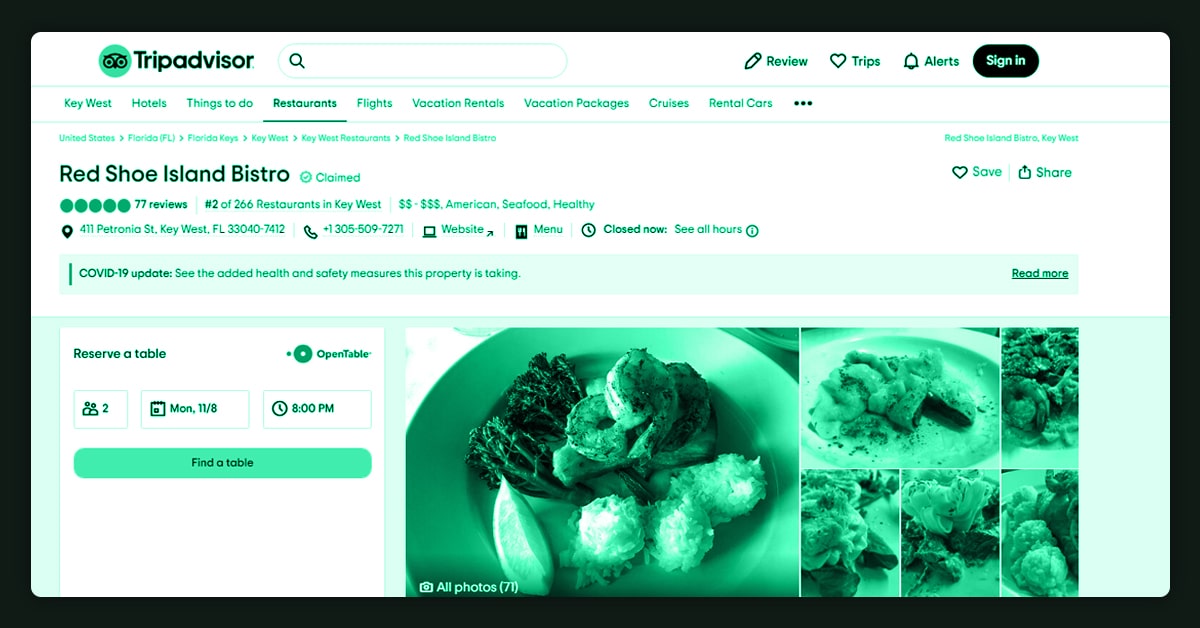
TripAdvisor.com is an excellent website to scrape as it contains a wide variety of information, including:
Hotels - Inbound and outbound searches, hotel ratings and reviews, images (maps), location, estimated prices, and general information such as the city and picture of the hotel.
Reviews: Inbound and outbound searches filtered by location, year, price range, and number of comments.
Attractions: It contains inbound and outbound searches filtered by location, time of year, price range (free or paid), and the number of images.
The above information is only an example of what you can scrape from TripAdvisor.com; many more things are helpful for your applications, such as restaurants, flights, etc.
Web scraping has many different benefits over other methods of data collection, including:
More Accurate Data: Web scraping typically returns more accurate data than free APIs, thanks to its ability to access confidential data behind walls, making it more precise and reliable.
Data Ingestion Speed: Web scraping can significantly speed up the process of collecting large amounts of data, especially compared to APIs (which require users to wait for servers to respond).
Data From Any Location: The great thing about web scraping is that you can collect data from anywhere worldwide. In contrast, most APIs only access data specific to certain regions.
Reusable Code: After collecting data from a website, you can use it in your applications by changing the code.
While web scraping is excellent in theory, it's important to remember that what you scrape will be used against your website, meaning you'll need to know where to draw the line regarding what you scrape.
Scraping websites is only sometimes legal. Depending on the data you scrape, you may need to pay for a license or seek permission from the website's owner. For example, if you're scraping reviews, you'll need to ensure that the copyright terms and conditions do not include restrictions on how reviews are used. You'll also want to avoid scraping competitors' data and any data derived from this data (e.g., the price of hotel rooms during peak vs. non-peak seasons). To help clarify the legality of web scraping, we've listed a few scenarios below:
Scenario 1: Buying a hotel room from TripAdvisor using a credit card. In this case, you're receiving payment for the service provided. In return, the TripAdvisor Terms and Conditions include a license agreement that permits TripAdvisor to use your data.
Scenario 2: You're using reviews from TripAdvisor to make price comparisons with other hotels or attractions. In this case, you don't intend to profit from others' data, so you should be under no obligation, legal or otherwise. However, you must be more careful if you scrape personal details such as phone numbers and email addresses. It's also best not to scrape credit card details due to fraud and theft concerns.
Scenario 3: You're creating an application that helps users find hotels near them. In this case, you should indicate what happens to the data when it's used in the service and ask for permission from the website for their data.
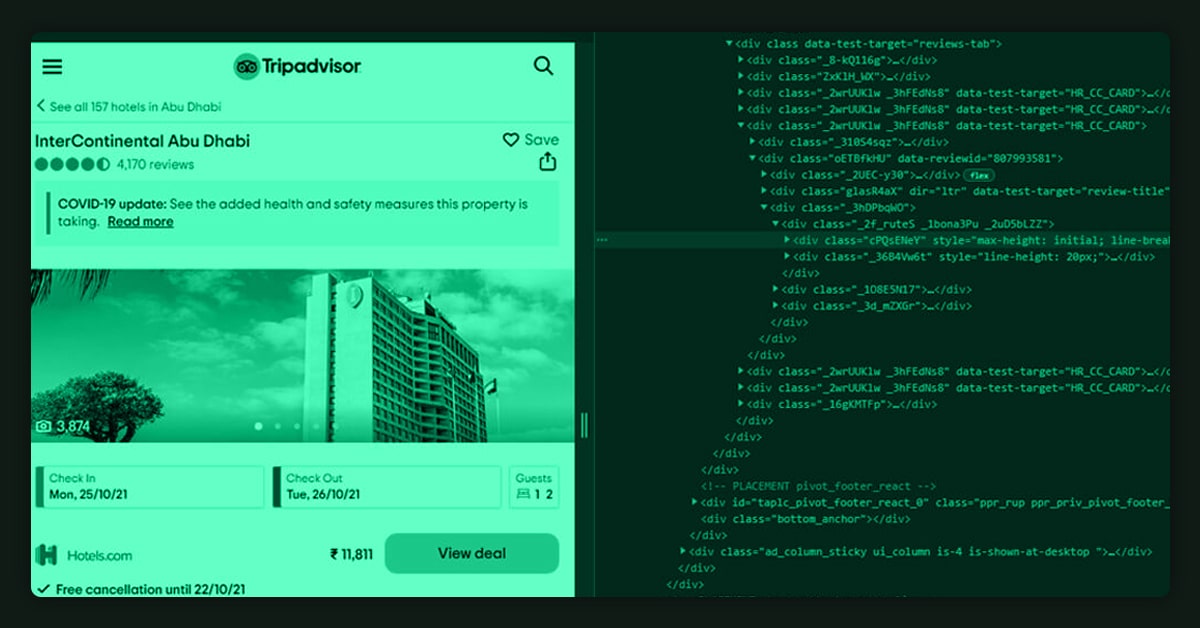
To begin scraping TripAdvisor, you'll need to purchase some tools and learn how to download and install a web scraping toolkit. For example, if you're using Python, we recommend the Requests library (compatible with Python 2.7 and 3+) or Selenium; alternatively, Java can be used with Scrapy (recommended by many experts). You can also use the following websites to help you choose the best web scraping tools:
One of the most famous integrated tools is Import.io, which allows you to build a scraper with just a few clicks quickly. It is your best option if you want to avoid making your scraper. Import.io has an excellent interface that's simple enough for novices to understand and powerful enough for experts to manage thousands of data sources and millions of records. In addition, its deep integration with Google Chrome and Firefox makes it incredibly easy to scrape data from any website on the Internet (some other mainstream browsers are also supported). Scrapy is a Python-based web scraping tool known for its ease of use. You can set up a project with the most basic data collection through a few clicks or integrate it with other tools such as Google Chrome, Firefox, and Microsoft Edge. It makes it ideal for beginners who are just getting started in web scraping. Alongside these benefits, Scrapy has an excellent community and many tutorials on using its features to extract data from websites.
Before you can access sensitive information, you must ensure that the site you're planning on scraping doesn't have any security measures against non-authorized access (known as "hacking"). For example, most sites have protection from robots and crawlers, tools that gather information automatically. While this is effective against bots, it doesn't stop humans from scraping the site. These measures typically include blocking IP addresses or using captchas, which are visual tests to ensure that a human is accessing the website, not a bot. The best way to work around this is by using virtual private networks (VPNs). It will mask your IP address to access most websites without detection.
Once you've bypassed the security measures, you can start collecting data from the site. It can be done through various technologies (e.g., cookies, JavaScript, HTML5, and more), but for this tutorial, we'll focus on just one: web scraping.
Web scraping is an automated process by which you access data from a website using different web applications, typically called "scrapers" or "crawlers." These scrapers can be used to search through most websites using the same techniques. It means you can use almost any technology or language you want and still scrape data from websites without learning any different coding languages (e.g., PHP).
While this is great in theory, it's important to remember that all the information you scrape is publicly available on the Internet, including sensitive details such as credit card numbers and bank account details. It means you need to be cautious about where you're scraping from.
Web scraping is a powerful tool to extract data from websites and is helpful for both large and small business applications. It allows you to collect, organize and manipulate data from different websites without signing up or logging in. It can be valuable for collecting consumer information, tracking competitor pricing, detailing the costs of products or services, understanding consumer behavior, and more.
Scraping websites is only sometimes legal. Depending on the data you scrape, you may need to pay for a license or seek permission from the website's owner. For example, if you're scraping reviews, you'll need to ensure that the copyright terms and conditions do not include restrictions on how reviews are used.
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2026 ReviewGators, All rights reserved.
Disclaimer : Reviewgators.com only extracts or scrape the information or the data that is publicly available as well as does not scrape personal or identity-related information.
