
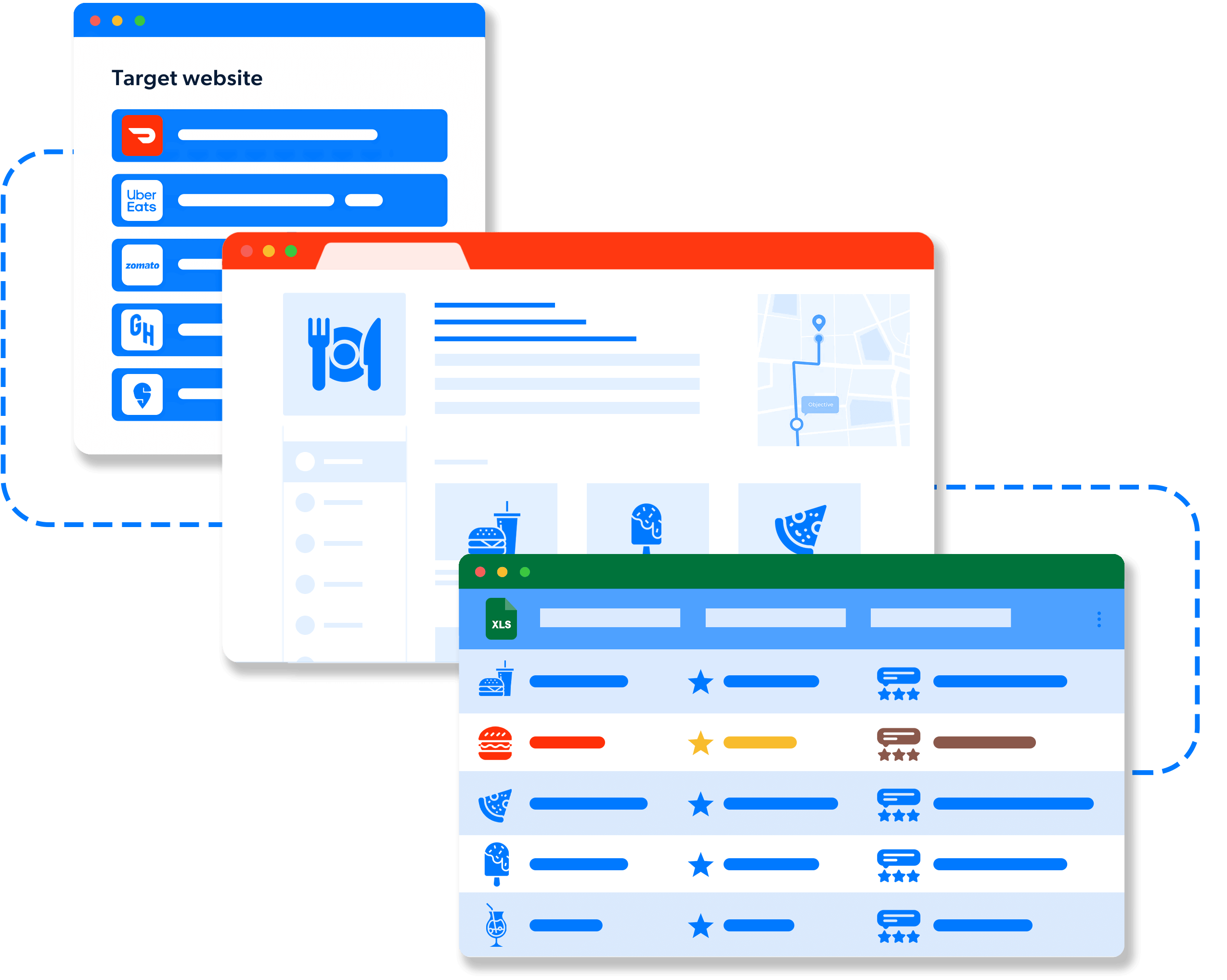
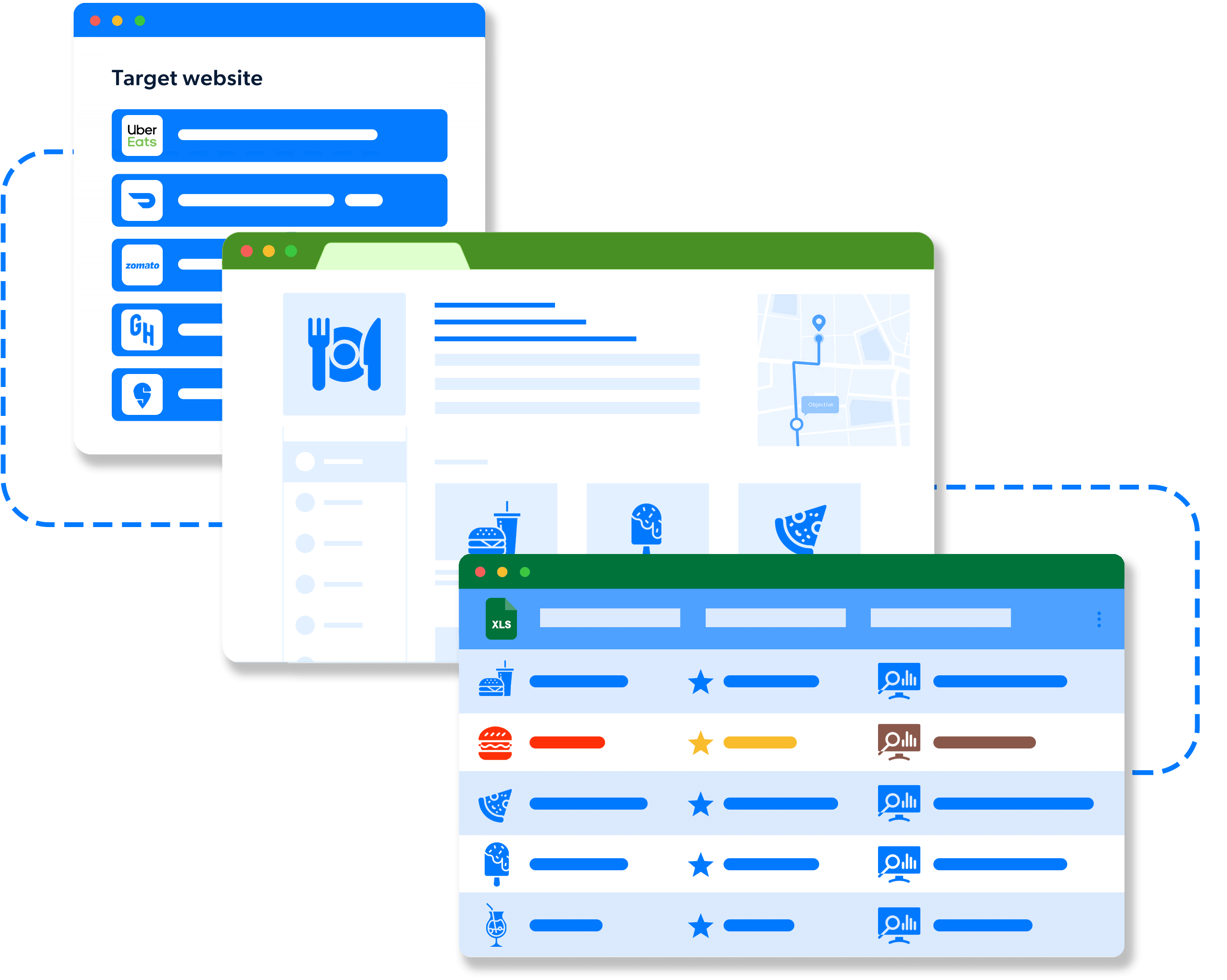



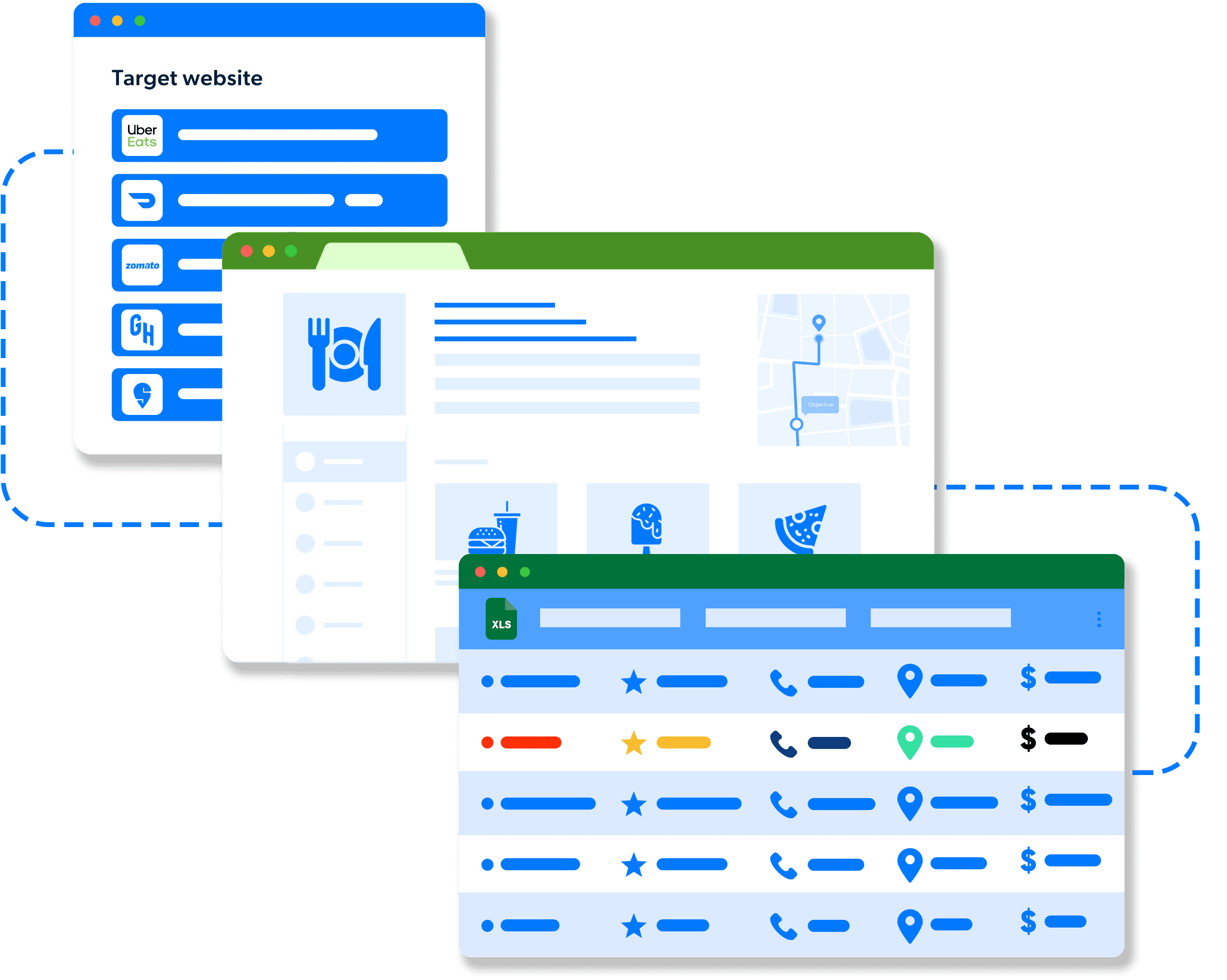
- Reviewer Name
- Review Date
- Review Title
- Star Rating
- Review Content
- Reviewer Profile Picture
- Reviewer Location
- Review Helpful Count
- Review Responses
- Mentioned Dishes
- Visit Date
- Restaurant Name
- Restaurant Location
- Review Tags/Keywords
- Verified Diner Status
- Review Language
- Review Source
- Review Photos
- Review Videos
- Service Rating
- Food Rating
- Ambiance Rating
- Price Range
- Dietary Preferences Mentioned
- Wait Time Mentioned
- Reservation Status
- Occasion
- Reviewer Followers Count
- Review Length
- Review Moderation Status




Testimonials